QVIM AES 2025 Challenge
The Challenge
The goal of the 'Query-by-Vocal-Imitation' (QVIM) task is to retrieve a specific sound effect from a large database based on a user's vocal imitation of that sound. The challenge lies in bridging the significant acoustic gap between a human voice and a real-world sound event.
My Role & Collaborators
On this project, I was responsible for the end-to-end system design and implementation. I developed the core ensembling logic, fine-tuned the four pre-trained audio encoders (MobileNetV3, PANNs, PaSST, BEATs), and implemented the class-aware fusion strategy. My collaborator, Vivek Mohan, provided invaluable support in researching data augmentation techniques and co-authoring the final report.
Our Solution
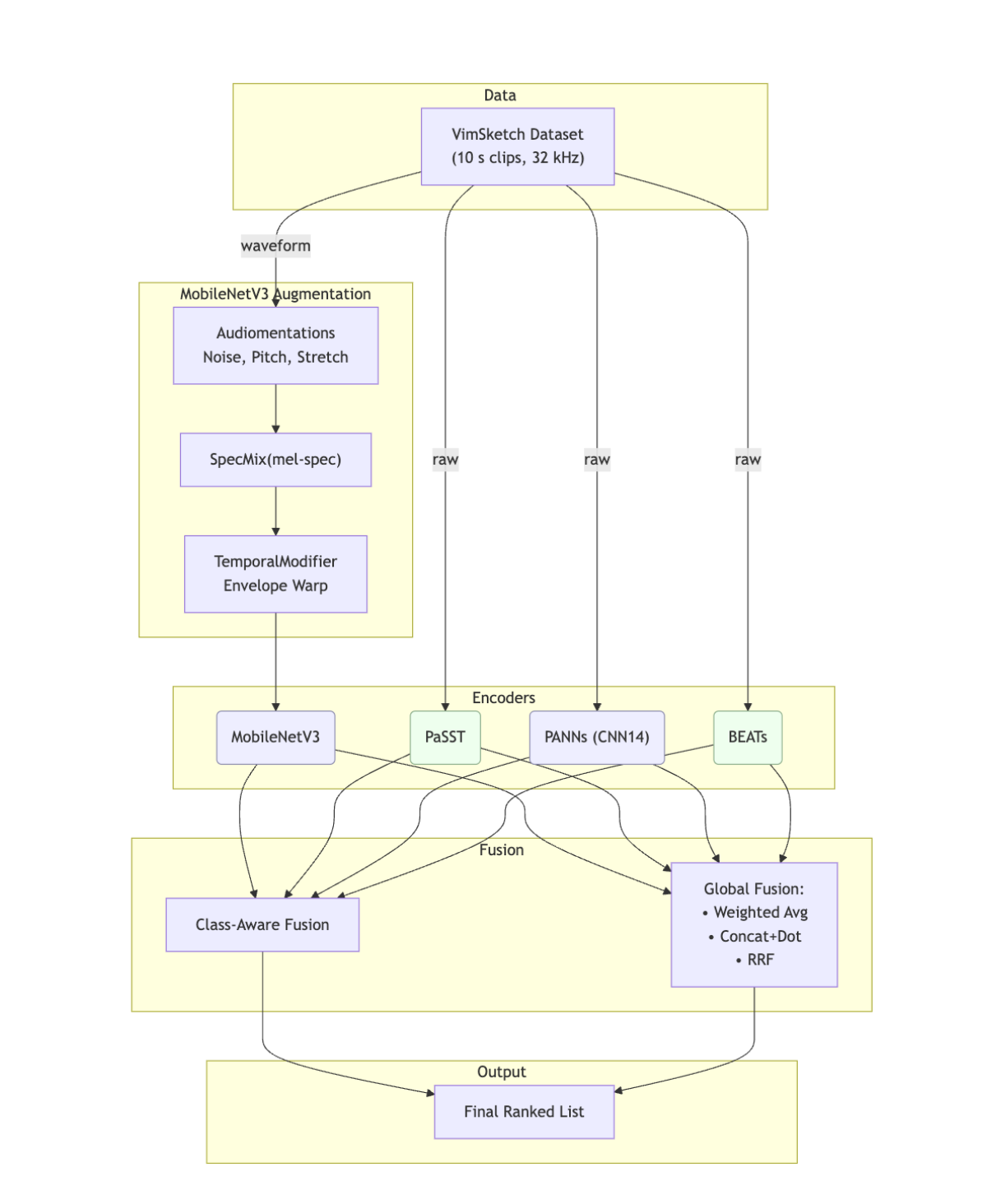
Our top-performing system was a 'Class-Aware Mixture-of-Experts' ensemble. We fine-tuned four distinct audio encoders on paired vocal-imitation and sound data using a contrastive (InfoNCE) loss. At inference, instead of treating all models equally, we dynamically weighted their contributions based on pre-calculated, per-class MRR scores. This allows the system to rely on the 'expert' model most suited for a given sound class (e.g., using a model that's good at 'wind' for a 'wind' query).
Key Techniques
- Ensemble of four pre-trained encoders: MobileNetV3, PANNs, PaSST, and BEATs.
- Contrastive fine-tuning using InfoNCE loss to create a shared embedding space.
- Class-Aware Mixture-of-Experts fusion based on per-class MRR scores.
- Softmax-weighted averaging to blend model outputs.
- MRR-targeted data augmentation pipeline for the MobileNetV3 model.
Project Links
Results
The Class-Aware system (System 1) achieved the highest performance, with a final MRR of 0.3191 on the validation set. This significantly outperformed the challenge baselines and demonstrated the benefit of a dynamic, class-specific fusion strategy over static ensembling.
System Architecture