DCASE 2025 SELD Challenge
The Challenge
The DCASE 2025 Challenge (Task 3) focused on Sound Event Localization and Detection (SELD) in stereo audio. The primary difficulties were accurately performing joint detection, direction-of-arrival estimation, and distance estimation, especially with the significant class imbalance present in the STARSS23 dataset.
My Role & Collaborators
I co-led this project, focusing on the core model architecture and performance. My main responsibilities included designing and implementing the Conformer-based ensemble, developing the feature extraction pipelines in Rust for performance, and training the models. I collaborated closely with my partner, Arjun Bahuguna, who was instrumental in the synthetic data generation using SpatialScaper and co-authoring the technical report.
Our Solution
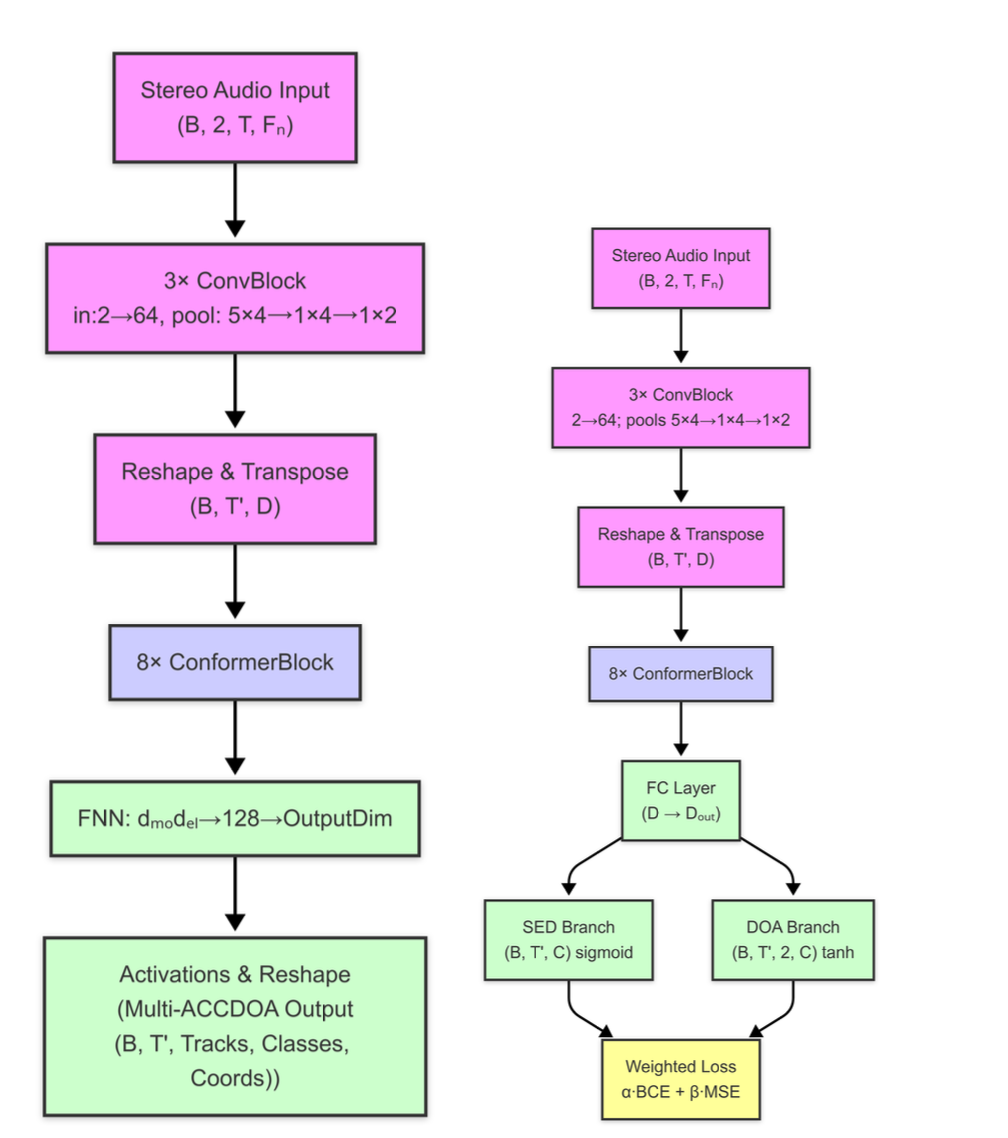
We proposed a 'winner-takes-all' ensemble of two specialized Conformer models: one for the full 3D SELD task (multi-ACCDOA) and another expert model for just SED and DOA. This allowed the system to dynamically select the most reliable prediction at each time frame based on pre-calculated, per-class performance metrics. To combat data scarcity for rare classes, we leveraged SpatialScaper for synthetic data generation and applied augmentations like channel-swapping.
Key Techniques
- Conformer-based model architecture for sequence modeling.
- Multi-ACCDOA output format for joint 3D SELD.
- Task-specific SED-DOA model with a weighted loss function.
- Frame-level 'winner-takes-all' ensembling strategy based on performance lookup tables.
- Synthetic data generation with SpatialScaper to address class imbalance.
Project Links
Results
Our ensemble model achieved a final F-score of 28.0%, a DOA error of 17.3°, and a relative distance error of 0.43 on the development set, outperforming the challenge baseline and demonstrating the effectiveness of our specialized ensemble strategy.
System Architecture